Human Level Performe to Sentiment Classification of Movie Review
1. Introduction
Because of the psychological nature of reviews, sentiment analysis (SA) of flick reviews is a challenging task for the researchers. SA is the procedure of manipulating textual media and extracting the subjective value from the text. It determines the review writer's attitude towards a movie: whether information technology is positive, negative, or indifferent. SA is currently being used all over the internet for various purposes such as political profiling, recommendation engines, fact checking, spam filtering, etc. Information technology has chop-chop generated a lot of attention among researchers working with machine learning and Tongue Processing (NLP), primarily considering information technology takes in crude text from a plethora of sources and transforms information technology into useful information. With the appearance of social media, the amount of data on the internet has boomed. Be it reviews, tweets, comments, poetry, stories, articles, or blogs, these resources can be tapped into and utilised by users. In the industrial sense, SA is mostly used by corporations to become and consider their customers' feedback. The field of NLP is intertwined with that of SA. Most information on the internet is present in the grade of natural text, unrecognizable to the machines due to their complexities and inter-word semantics. NLP is the procedure used in analysing these natural texts in lodge to class entities that tin be understood past the machine for SA. We used various methods to process and classify these moving picture reviews into one of the three classes—positive, negative, or neutral. The first step in the process was to clean the reviews past removing emojis, punctuation marks, numbers, and stop words that provide no meaningfulness to the text. It is also of import to derive the inherent sentiments in that text, which we achieved by further extracting features out from the texts and using them to classify these texts. Our study included the following steps:
-
Word-embedding: We used several discussion embedding techniques for characteristic extraction and in society to discover the semantics of the words in the cleaned version of the reviews. We used word2vec-skipgram, word2vec-CBOW, Google pre-trained word2vec, and GloVe;
-
Feature Pick: Past using feature-selection algorithms, we narrowed downwards the available features to the almost important ones. We used 3 filter methods—Chi-squared, F classifier, Mutual information (MI), and one wrapper method—Recursive Feature Elimination (RFE). All were used with meridian-one thousand features, where thousand was optimised;
-
Classification: We used three different classifiers with the following methods: Random Forest (RF), XGBoost (XGB), and Support Vector Classifier (SVC).
Our study contributes to the field in a way that it provides noteworthy results to the area of three-class classification with an entirely new database that nosotros freshly scraped from IMDB. Nosotros named our dataset JUMRv1—Jadavpur Academy Movie Recommendation dataset version 1.
The balance of the paper is organised in the post-obit way: Section 2 deals with previous work that has been performed on the topic. Department three gives an insight into the dataset that we considered for our written report. Department 4 throws low-cal upon the methodology that was followed for the study, a journey from raw data to sentiment classification. Department 5 is a detailed description of the results that we received. Section 6 analyses the results and provides explanations for them. Finally, Section 7 concludes the inquiry, summing information technology up and providing improvement opportunities.
ii. Literature Survey
In the by couple of years, researchers have worked on diverse recommendation systems based on text data provided past netizens. Baid et al. [1] proposed a study based on the "Sentiment Polarity Dataset version 2.0" from the IMDB website (Pang and Lee [2]), which is a two-class dataset. The classifiers used were Naïve Bayes (NB), 1000-Nearest Neighbour (KNN), and RF. The word embedding was provided by the StringToWordVector filter. Elghazaly et al. [iii] presented a political SA model that used twitter information. They utilised Term Frequency-Inverse Document Frequency (TF-IDF), which is a term weight-based embedding organization, combined with simple Naive Bayes (NB) and Support Vector Motorcar (SVM) classifiers. Pratiwi et al. [4] besides as Adwijaya used document frequency-based vocabulary but implemented feature selection based on information gain. SVM and Neural Network (NN)-based models were used to allocate reviews in the the same dataset as Baid et al. [i].
Pang et al. [5] and Lee worked on the SA of IMDB movie review data using unigram, bigram, and uni+bigram models. They used NB, Maximum Entropy, and SVM classifiers to achieve a two-course classification. Tripathy et al. [6] and Zou et al. [seven] furthered the piece of work of Pang et al. [5] past calculation TF-IDF, POS tagging, and Stochastic Gradient Descent (SGD) in order to meliorate the accuracies. Ukhti Ikhsani Larasati et al. [eight] developed the work of Tripathy et al. [half dozen] and used the chi-squared method of feature selection along with the already proposed SVM classifier.
Ray et al. [9] proposed a hotel recommendation organisation using a sentiment analysis of the hotel reviews and an aspect-based review categorisation that works on the queries given past a user. They provided a new rich and diverse dataset of online hotel reviews crawled from Tripadvisor.com. They followed a systematic approach, which first used an ensemble of a binary nomenclature called the Bidirectional Encoder Representations from Transformers (BERT) model, with three phases for positive–negative, neutral–negative, and neutral–positive sentiments merged using a weight assigning protocol. The authors also grouped the reviews into dissimilar categories using an approach that involved fuzzy logic and cosine similarity. Finally, they created a recommender organisation with the same frameworks. Our model achieved a Macro F
-score of 84% and test accurateness of 92.36% in the classification of sentiment polarities.
Fang and Zhan [10] put forward a product review-based recommendation system from reviews on Amazon.com. Their categorisation was both review-based and judgement-based. Part-of-oral communication (POS) tagging and sentiment-phrase identification were performed to calculate a sentiment score. These were considered, along with the rating system, which allowed users to rate the product from one-half to five stars. This two-level scoring system was combined with NB, RF, and SVM classifiers.
Barkan and Koenigstein [11] provided an embedding method based on collaborative filtering using the word2vec skip-gram negative sampling method (SGNS) named 'item2vec'. This was used on a music dataset with artists pertaining to several dissimilar genres. When compared to a singular value decomposition classified with a elementary KNN model, the embedding resulted in a more authentic score.
Manek et al. [12] used opinion mining based on the Gini index by extracting opinion-oriented words (top l words). When performed on several spider web and self-crawled databases, the outcome was fed to an SVM classifier. This method does not account for sentences that may contain unopinionated words and yet carry opinions, nor does it deal with sentences that might contain strong polarising words and notwithstanding non contain important opinions. Both these works were based on ii-form nomenclature.
Liao et al. [xiii] propounded the use of a deep learning-based classifier forth with MR and STS-Gold equally the benchmark datasets (Saif et al. [14]) to give a two-class nomenclature. The NN used was CNN, which contained iii convolution layers with 3 max pooling layers, and a softmax layer. The achieved results were better than traditional classifiers such every bit SVM and NB. Singh et al. [15] put along a Recurrent Neural Network (RNN)-based multilingual movie recommendation arrangement. A twitter API was used to search for moving-picture show details, which provided user comments on the movie. Google maps was used to observe the geographical location of the user and the information were translated using Google translator. Later on, the data were fed to the Stanford NLP library in order to create the word embedding. An RNN was used to categorise the reviews into positive or negative classes.
Ibrahim et al. [16] used an RNN and Long Short Term Memory (LSTM)-based recommendation model on various datasets such as Twitter, Rotten Tomatoes, etc. Word embedding was provided by SenticNet word network based on the semantics of the words. Uni-gram, bi-gram, and tri-gram texts were fed to the SVM classifier. This model utilises the concept of an LSTM jail cell, which helps to consider the relationships of a give-and-take with words after and before information technology, providing a better semantic organization of words. Wang et al. [17] proposed an "RNN Capsule" method. This method assigns 1 capsule to each class and uses that capsule's state and attributes to learn and classify the reviews into positive or negative. This takes away the demand for linguistic knowledge by using discussion embeddings.
Firmanto et al. [18] and Miranda et al. [19] proposed an effective model based on better give-and-take embeddings using SentiWordNet. Information from Rotten Tomatoes and Twitter information, respectively, were fed to the SentiWordNet library, which provided a sentiment score for the reviews based on the polarities of specific words present in the library. These scores were then added to detect the total, which decides the polarity of the entire review.
In domains related to film review sentiment assay, three-class categorization has been a popular subject area. Hong et al. [twenty] provided a 3-class sentiment classifier, with book reviews on amazon.com as the corpus. Word2vec word embeddings and several simple and neural-network classifiers were used. Attia et al. [21] propounded a multi-lingual, multi-course sentiment classifier using twitter corpus data for English, German language, French, etc. TF-IDF was used along with a CNN for nomenclature. Sharma et al. [22] avant-garde the work of Liu et al. [23] and proposed an ensemble method for a mutli-class sentiment classifier using SVM and bagging techniques.
3. Dataset
In the present work, we developed a new dataset called JUMRv1, which is to be used in movie recommendation research. We named our dataset in this way every bit this was prepared in the lab of Jadavpur University, Kolkata, India. Scraped from the Internet Movie Database (https://world wide web.imdb.com/search/title/?title_type=characteristic,tv_series&count=250&start=001&ref_=adv_nxt, accessed on x May 2020), JUMRv1 consists of the top 25 reviews for 60 movies, totalling 1500 reviews. We used the Beautiful Soup 4 library (Richardson [24]) for the scraping. The reviews were annotated as ane, 0, or −1, representing positive, negative, and neutral categories, respectively.
Annotating, though boring, is a step of extreme importance every bit this is going to be reflected in the final dataset that has to exist fed to the classifiers. While some reviews were clear and condensed, many reviews were from professional critics who used comprehensive explanations, analogies, and metaphors that were mostly directed at cinema enthusiasts. We ensured constant communication in gild to sustain maximum F
scores in these annotations. As expected, the annotations revealed some class imbalance. That is, 1 category outnumbered the others. The class imbalance found in the adult database is as follows (in terms of number):
-
Positive (1): 833
-
Neutral (0): 301
-
Negative (−1): 288
The problem with making tongue datasets is the complication of homo language, with new words creeping into use every day and new semantics arising out of these new words. The addition of the neutral grade to the annotation makes the database-making process even more difficult. Some examples taken from JUMRv1 are shown in Table ane.
In Tabular array ii, a comparison betwixt the iv most popular movie review sentiment analysis datasets and JUMR v1.0 is provided, in terms of when they were last updated, when they were created, how many reviews they concur, and how many classes they have. From this table, it is clearly seen that JUMRv1 holds an advantage over the rest as it provides both comparatively newer movie reviews every bit well every bit annotates the reviews into 3 different classes. On the other hand, the most popular datasets only provide a 2-course classification and a rather sometime set of movies, most of which are irrelevant today.
The dataset has reviews which vary from existence sarcastic and ironic to serious and straightforward. This variation of behaviour has resulted in difficulties in the experiments performed to railroad train the classifiers, and has led to a decrease in classification F
scores, as seen in the result section. Nosotros created a 70:30 railroad train-test split of the dataset for experimentation purposes.
4. Methods and Materials
The methodology that we followed is similar to the 1 proposed past Sharma and Dey [25]. In our enquiry, the inherent parts include scraping the information from the IMDB website, text pre-processing, creation of a give-and-take network, feature extraction, feature selection, and sentiment nomenclature. The workflow of this research is illustrated in Figure 1.
iv.1. Pre-Processing
During the creation of JUMRv1, we discovered that textual information in online reviews are written in complex natural man language, which consists of English words (in our instance), connector words, different parts of speech communication, conjunctions, interjections, prepositions, punctuation marks, numbers, emojis, html tags, etc. All these components do not necessarily add together value to the text, peculiarly for the SA chore. After the web-scraping process, nosotros used the text cleaning method as proposed by Rahman and Hossen [26] in order to clean the reviews. The method is given beneath:
-
Removing non-alphabetic characters, including punctuation marks, numbers, special characters, html tags, and emojis (Garain and Mahata [27]);
-
Converting all letters to lower case;
-
Removing all words that are less than iii characters long equally these are not likely to add whatever value to the review as a whole;
-
Removing "finish words" includes words such as "to", "this", "for", as these words do not provide pregnant to the review every bit a whole, and hence will not assist in the processing;
-
Normalising numeronyms (Garain et al. [28]);
-
Replacing emojis and emoticons with their respective meanings (Garain [29]);
-
Lemmatising all words to their original form—so that words such every bit history, historical, and historic—are all converted into their root word: history. This ensures that all these words are candy as the same word; hence, their relations go clearer to the motorcar. We used the lemmatiser from the spaCy (Honnibal et al. [xxx]) library.
iv.2. Word Embedding
Word embedding is a method of representing words in a depression-dimensional infinite, most commonly in the form of real-valued vectors. It allows words with similar significant and related semantics to be represented closer to each other than less related words. Word embeddings assistance attach features to all words, depending on their usage in the corpus. In other words, the purpose of discussion embeddings is to capture inter-word semantics. Figure ii shows a typical give-and-take embedding.
While working on JUMRv1, we dealt with ii dissimilar approaches to give-and-take embeddings, namely Word2Vec and GloVe.
Word2Vec: This is a two-layer NN that vectorises words, hence creating a word embedding. This method works by initialising a random word with a random vector value. It then trains the word according to its neighbouring words in the corpus. Word2Vec models can be customised to have a wide range of vocabularies, a big number of features every bit well equally embedding types. In that location are also some pre-trained Word2vec models, attainable via open sources (https://towardsdatascience.com/the-iii-chief-branches-of-word-embeddings-7b90fa36dfb9).
GloVe: GloVe stands for Global Vectors and refers to a method of vectorising all the words given in a corpus while considering global likewise as local semantics, unlike Word2Vec, which just takes care of local semantics. This method counts the total number of times ane word co-occurs with another word with the use of a co-occurrence matrix; the resultant embedding is made on the basis of relative probabilities.
In this study, we used four unlike types of discussion embeddings, three of which are Word2Vec types and one is of the GloVe type. These are the following:
-
Google Pre-trained Word2Vec: This is a Word2Vec model, trained past Google on a 100-billion-word Google News dataset and accessed via the gensim library (Mikolov et al. [31]);
-
Custom Word2vec (Skipgram): Here, a custom Word2Vec model that uses "skipgram" neural embedding method is considered. This method relates the key word to the neighbouring words;
-
Custom Word2Vec (Continuous Purse Of Words): Some other custom Word2Vec model that uses the Continuous Pocketbook Of Words (CBOW) neural embedding method. This is the opposite of the skipgram model, as this relates the neighbouring words to the central word;
-
Stanford University GloVe Pre-trained: This is a GloVe model, trained using Wikipedia 2014 (Pennington et al. [32]) every bit a corpus by Stanford University, and can exist accessed via the academy website.
Among these, the get-go three are Word2Vec-type embeddings and the fourth is a GloVe embedding. Word2Vec embeddings have a neural network that can train itself with two learning models: CBOW and Skipgram.
CBOW: In this method, the representations of the neighbouring (context) words are fed to the NN to predict the word in the eye. The vectors of the context words form the vector of the give-and-take in the center. Error vectors are formed and the private weights are averaged before passing each word through the softmax layer.
Skipgram: Here, the exact opposite route is taken. The discussion in the centre is fed to the NN. Error vectors are formed with all words that could possibly be adjacent. The error vectors are calculated and using back propagation, the weights of the hidden layers are updated accordingly. Figure three shows a graphical representation of these two methods.
We performed a majority of the exhaustive testings on the Google and Stanford pre-trained embeddings due to the more than promising nature of results.
4.3. Characteristic Extraction
Feature extraction maps the original feature space to a new feature space with a lower or the same number of dimensions by combining the original feature space but with better representation. In our study, we used four word embeddings. Of these four, the Google pre-trained word embedding had 300 features, the GloVe pre-trained embedding had 200 features, and the two Word2Vec embeddings that nosotros trained (Skipgram and CBOW) had 100 features each. Instead of making manual attempts to devise feature vectors for all words in the vocabulary, nosotros took a dissimilar approach. We calculated the boilerplate embeddings of every word. This can be explained past Equation (i):
where West is a word,
is the vector for the word, eastward(West) is the embedding for the give-and-take, and
is the total number of words in the vocabulary. Embeddings tin can be obtained by because the model function with the word a parameter. These are essentially the coordinates to every discussion in the multi-dimensional vector infinite. This contrasts with the otherwise popular method of assigning vectors to packets or entire documents, where the information loss is significant.
4.four. Feature Choice
Characteristic choice (Miao and Niu [33]) refers to the process of choosing only the essential features which volition have a positive impact on the chore of classifying the information into the required labels. Whenever loftier-dimensional data are used with a lot of features, they oftentimes comprise some not-informative and redundant features that hamper the process of nomenclature, a phenomenon known as the curse of dimensionality.
It has been documented in the work by Ghosh et al. [34] that not all features are equally important when performing a classification chore. Some features seem to have a constructive effect on accuracy, whereas some have a destructive result. Therefore, we tried to find out if a certain set of features that enhances the accuracy tin can be selected. According to whether the training fix, i.e., features under study, is labelled or not, feature selection algorithms can be categorised into supervised, unsupervised, and semi-supervised feature selection. Nosotros used only the supervised characteristic selection algorithms. The next part deals with the classification of supervised feature selection methods and also describes some of the feature pick methods that were employed in our study. Given below is the classification of feature selection methods based on the option strategy:
-
Filter methods;
-
Wrapper Methods;
-
Embedded Methods.
The filter method of the feature option separates feature pick from classifier learning and so that the bias of a learning algorithm does non interact with the bias of a feature option algorithm. Information technology relies on measures of the full general characteristics of the training data such as distance, consistency, dependency, information, and correlation. Based on the advantages of filter methods as reported in Ghosh et al. [34], in the present study, we chose three filter-based feature option methods. Nosotros also experimented with ane wrapper-based feature choice method. The wrapper model uses the predictive accuracy of a predetermined learning algorithm to decide the quality of selected feature subsets and ultimately to choose the optimal ones. Figure 4 shows the workflow of a feature selection method.
These methods are prohibitively expensive to run for information with a large number of features, but they requite commendable results. Given below are the characteristic selection methods that we used in our report.
iv.4.1. Filter Methods
Chi-Squared
Chi-squared is a statistical test that measures the divergence from the expected distribution if the occurrence of a feature is causeless to exist independent of the class value (Forman et al. [35]). The chi-squared exam measures dependence betwixt stochastic, well-defined variables; hence, using this function eliminates the features that are the nigh likely to exist independent of class and therefore irrelevant for classification. It does so with the use of the chi-squared metric. In the case of continuous variables, the range needs to exist divided into intervals (Li et al. [36]). This chi-squared metric, which is too treated as the value of each feature, is given in Equation (two):
where, r is the number of distinct values in the feature, c is the number of distinct values in a class,
is the frequency of jth element with southwardth grade and
,
is the frequency of jth element, and
is the total number of elements with sth class. A college chi-foursquare value indicates that the feature is more informative.
F-Classifier
This is used to discover the Analysis of Variance (ANOVA) f-value. ANOVA tin determine whether the means of iii or more groups (features in this case) are different. ANOVA uses F-tests to statistically test the equality of means.
F-tests are named afterward its examination statistic. The F-statistic is just a ratio of two variances. Variances are a measure of dispersion, or how far the information are scattered from the mean. Larger values correspond greater dispersion. Dispersed data ways the characteristic will not be that useful considering this can exist an indication of racket in the information. Therefore, basically, it is used to filter out co-related features.
More importantly, ANOVA is used when one variable is numeric and i is chiselled, such as with numerical input variables and a classification target variable in a classification task. The results of this test can exist used for characteristic option where those features that are contained of the target variable can exist removed from the dataset.
Common Information
MI is based on the concept of entropy. Entropy is a quantitative measure of how uncertain an outcome is. This means that if an event has a greater probability of occurring than another, then its entropy is lower than the second event. In nomenclature, MI betwixt two random variables shows dependency between them. Minimum dependency gives nada MI, and every bit dependency rises, then does the MI.
If
,
, and
are the entropies of X, Y, and the joint entropy of X and Y, and so common information betwixt X and Y can be defined as shown in Equation (3):
The mutual data betwixt 2 discreet variables Ten and Y is given as shown in Equation (four):
where
is the joint probability density role for X and Y, and
and
are the marginal probability density functions for X and Y, respectively. MI is calculated between 2 variables by testing the reduction in dubiety of 1 variable, given a fixed value for the other. If MI does not exceed a given threshold, that characteristic is removed. This method can exist used for both numerical and categorical information.
4.4.2. Wrapper-Based Method
Recursive Characteristic Emptying
Given an external figurer that assigns weights to features (e.chiliad., the coefficients of a linear model), the goal of RFE is to select features by recursively considering smaller and smaller sets of features. First, the reckoner is trained on the initial prepare of features and the importance of each feature is obtained either through any specific attribute (such equally coef_, feature_importances_) or callable. And then, the least important features are pruned from the current fix of features. That process is recursively repeated on the pruned gear up until the desired number of features with optimal accuracy is somewhen reached.
4.five. Classification
We incorporated three standard classifiers into the iii-course classification job under consideration, for each of the combinations of embedding and characteristic selection mechanisms.
4.v.1. Random Forest
This is a bagging-type classifier and it is substantially an ensemble of individual decision trees. It incorporates a number of decision tree classifiers, trains them over various sub-samples of the dataset, and uses averaging to increase the predictive accuracy. The fundamentals behind the functions of a random wood classifier is that when a number of independent and uncorrelated decision trees work as a voted ensemble, they outperform all of these private models. Considering of this low correlation, in that location is randomness amidst these models.
four.5.2. XGBoost
XGBoost stands for extreme Gradient Boosting. Unlike the bagging technique that merges similar conclusion-making classifiers together, XGB is a boosting-type ensemble algorithm. Boosting is a sequential ensemble that uses different iterations to remove misclassified observations past increasing their weights with every iteration. Boosting keeps track of the learner's errors. Using parameters to control the maximum depth of decision trees beingness used and the number of classes in the dataset, the XGB model tin exist used to bargain with information that take a large variance. Boosting is completed sequentially instead of parallelly such as in bagging methods.
iv.five.iii. Support Vector Classifier
This algorithm is completely unlike from the previous 2, as its fundamentals involve finding a hyperplane in an N-dimensional infinite. The target is to maximise the support vectors.
Determination Boundary: This is a hyperplane that separates different classes of observations. The dimensionality of a hyperplane depends on that of the information. This just means that for two-feature
information, a hyperplane is a line, and for three-characteristic
information, it is a airplane.
Back up Vector: Support vectors are observations that prevarication closest to the determination boundary that influences its position and directionality. In the proposed written report, SVC has been used via the scikit-acquire package with the Radial Ground Part (RBF) kernel. These kernels are specified for hyperplanes that are non-linear, as real world data do not necessarily need to be linear.
v. Results and Discussion
As mentioned earlier, in this work, nosotros prepared a three-grade SA dataset chosen JUMRv1 for the evolution of moving-picture show recommendation systems. We likewise provided the required notation then that other researchers tin assess the performance of their methods. To set a benchmark consequence on JUMRv1, nosotros performed an exhaustive gear up of experiments. After extensive testing with dissimilar give-and-take embeddings and characteristic selection methods, too every bit with the SVC, RF, and XGB classifiers, the SA results have been categorised and are discussed below.
GloVe (Pennington et al. [32]) word embedding, developed by Stanford University Researchers, was trained on the entire Wikipedia corpus. It was used as a stand up-lonely with all 200 of its available features and forth with unlike feature pick methods, which were utilised to rank the importance of the features, employing 150, 100, and 50 of these in the experiments.
v.ane. Analysis Metrics
In social club to analyse the performance of our model on various datasets, we considered the standard operation metrics, namely the F
score and the accuracy score with their corresponding class support division.
Precision is defined as:
Accuracy score is defined as:
Hither, TP (True Positive) = Number of reviews correctly classified into respective sentiment classes.
FP (Faux Positive) = Number of reviews classified as belonging to a sentiment course that they exercise not vest to.
FN (False Negative) = Number of reviews classified as not belonging to a sentiment class that they actually belong to.
The F
score is defined as:
Support for a sentiment class is defined as the number of reviews that lies in that sentiment class.
Figure 5 shows the F
scores that we obtained using GloVe word embeddings with 200 features (i.e., no feature choice). Table 3 denotes the F
scores received via Glove embeddings, but with the help of different feature selection methods, selecting 150, 100, and fifty of the most of import features.
Google Word2Vec word embedding is one of the near popular embeddings used in NLP. Here, we used the Word2Vec pre-trained model, which was trained on the Google News corpus with 100 billion words in its vocabulary. It has 300 features and using different feature selection methods, we ranked these features and selected the top 150, 100, and 50 features accordingly.
Figure 6 shows the F
scores for Google's pre-trained Word2Vec embedding with all 300 features (i.due east., no feature selection). Table iv shows the Fi scores obtained on the same embedding upon selection of the top 150, 100, and l features.
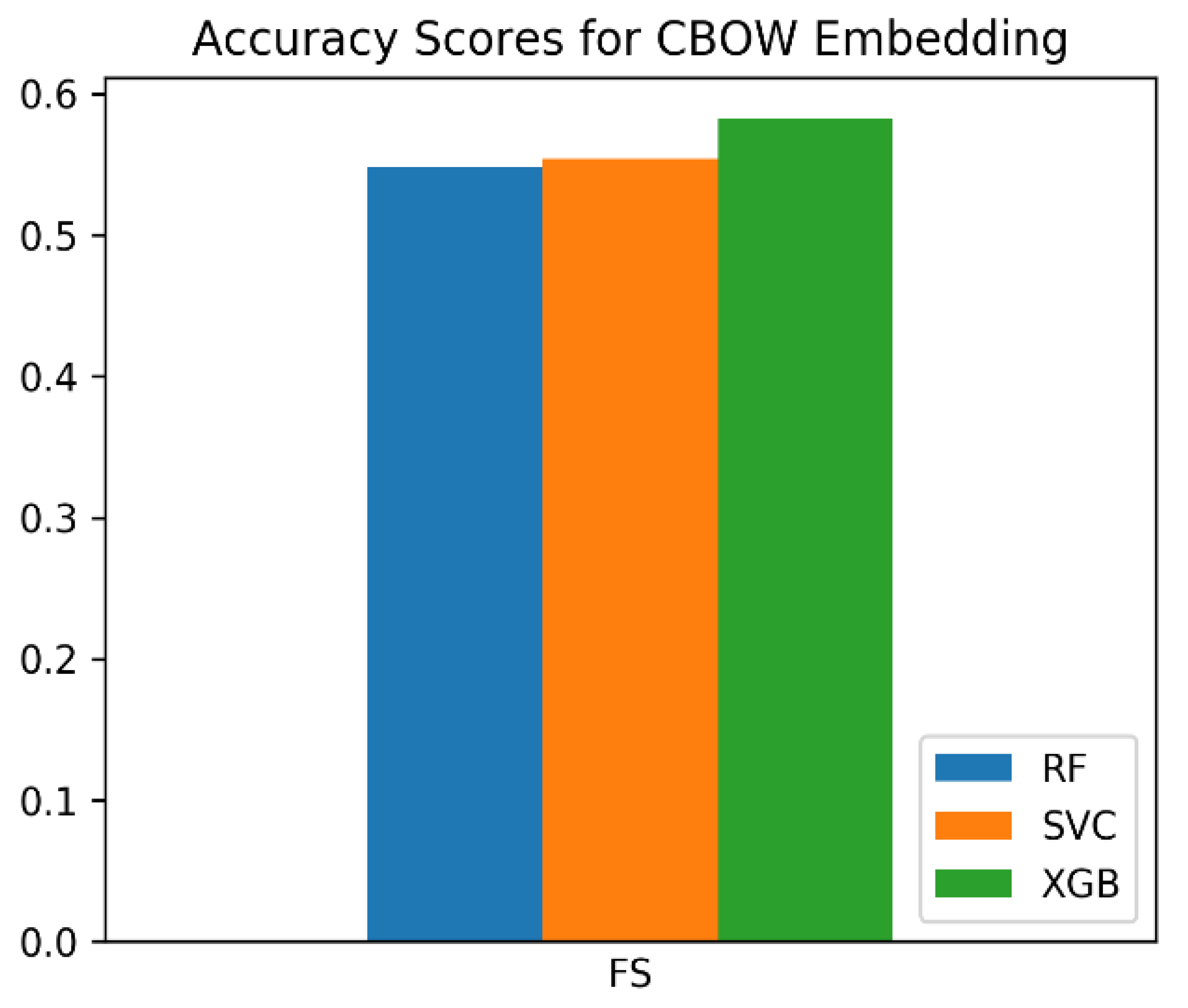
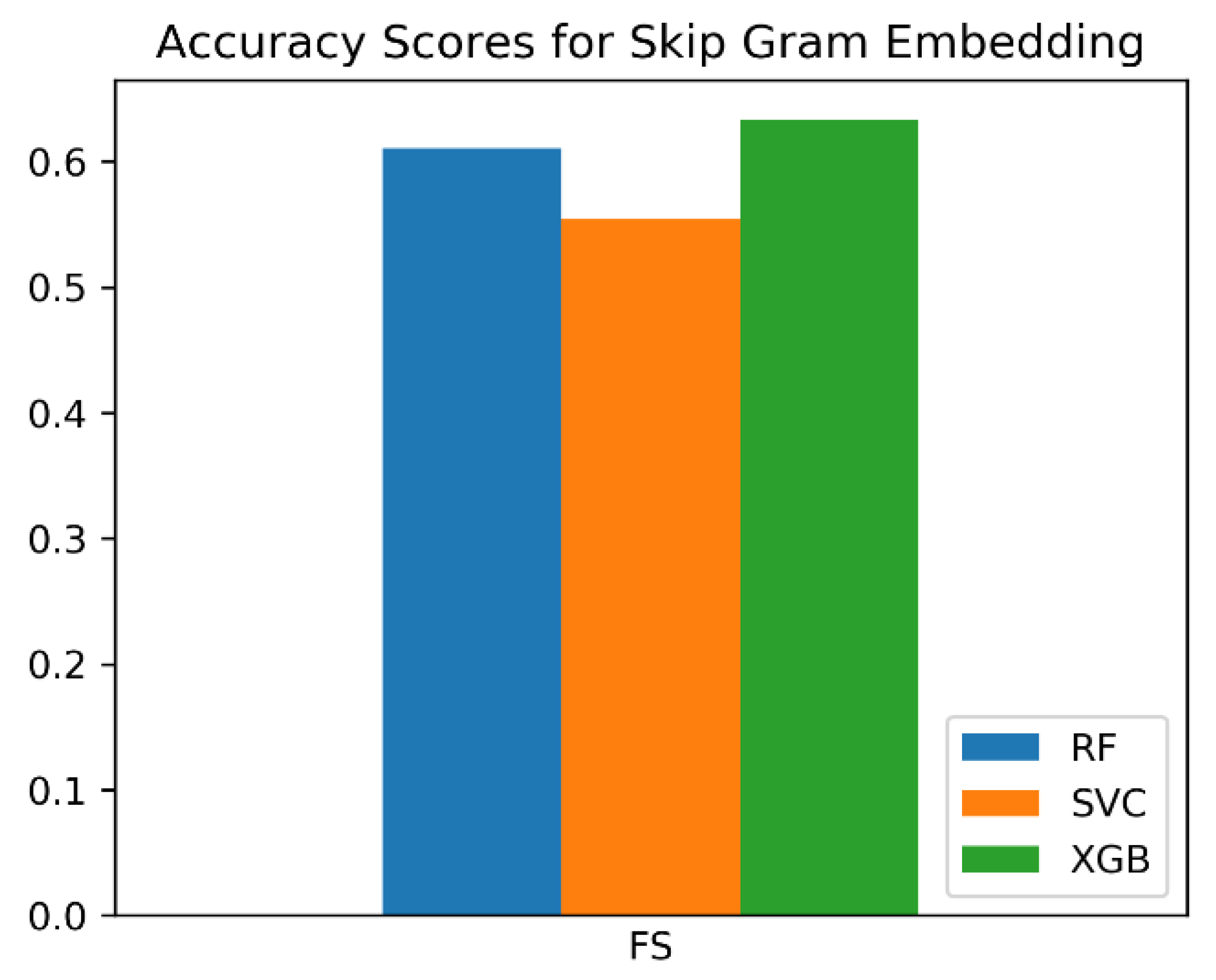
We too trained the Word2Vec model on our own data corpus using the CBOW approach once and the Skipgram approach once. The three classifiers—SVC, RF, and XGB—were as well used here. Although the F
scores were not that promising, they even so gave usa important insights about the data. The results are given in Table 5.
In Table 6, Table 7, Table 8, Table nine, Table x, Table 11, Tabular array 12, Table thirteen, Table 14 and Tabular array 15, defoliation matrices are given for the 10 most accurate models that nosotros accomplished, along with their precision and recall values. The classifier used for Table six is XGB, with an accurateness score of 0.6836 and the precision and recall being 0.6838 and 0.683, respectively. The F1 score is 0.66. The classifier used in Table 7 is the Random Forest Classifier, with an accurateness score of 0.689, precision of 0.689, recall of 0.689, and an F1 score of 0.689. The classifier used in Tabular array eight is the Random Forest Classifier with an accuracy score of 0.6836, precision of 0.6836, recall of 0.666, and an F1 score of 0.675. The classifier used in Table 9 is XGB, with an accuracy score of 0.6836, precision of 0.6836, call up of 0.666, and an F1 score of 0.675. The classifier used in Table x is XGB, with an accuracy score of 0.689, precision of 0.68, think of 0.686, and an Fone score of 0.682. The classifier used in Table 11 is XGB, with an accuracy score of 0.6892, precision of 0.664, recall of 0.672, and an Fane score of 0.668. The classifier used in Table 12 is XGB, with an accuracy score of 0.7005, precision of 0.vii, recall of 0.7, and an Fane score of 0.seven. The classifier used in Table thirteen is XGB, with an accuracy score of 0.7, precision of 0.7, retrieve of 0.68, and an Fane score of 0.69. The classifier used in Table 14 is SVC, with an accuracy score of 0.695, precision of 0.694, recall of 0.687, and an F1 score of 0.69. The classifier used in Table 15 is XGB, with an accuracy score of 0.6892, precision of 0.664, recall of 0.672, and an Fi score of 0.668.
The visual representation of the entire exhaustive testing procedure, marking all the different embeddings, feature selection methods, and classifiers are shown in Figure vii, Figure 8, Figure 9, Figure 10 and Figure 11.
Figure eight shows a similar exhaustive testing for the Google pre-trained embedding on the dataset.
Effigy ix shows the F
scores of all three classifiers on the CBOW Word2Vec database that we trained.
Effigy 10 shows the F
scores of all three classifiers on the Skipgram Word2Vec database that we trained.
Figure 11 lists the ways of the F
scores for all observations on the four word embeddings.
five.two. Software Used
To set a benchmark result for JUMRv1—the newly developed SA-based movie recommender dataset, we performed various experiments. For the purpose of implementation, we used different software: We used NumPy (Harris et al. [37]) and Pandas (pandas development team [38]) for Assortment and DataFrame operations. The spider web-scraper that we used to prepare the JUMRv1 tin can be found in the Cute Soup (Richardson [24]) library. For text cleaning, nosotros used Regular Expression (Van Rossum [39]), and for the lemmatisation, the SpaCy Lemmatizer (Honnibal et al. [30]). To create the give-and-take embeddings, the Gensim (Řehůřek and Sojka [40]) library was used for both Google's pre-trained and our cocky-trained Word2Vec, while GloVe (Pennington et al. [32]) had to be downloaded from the Stanford website. For the feature selection and classification methods, Scikit-Acquire (Pedregosa et al. [41]) was used. All graphical visualisations were performed using MatPlotLib (Hunter [42]).
6. Assay
An analysis of the aforementioned results indicates the following trends:
As nosotros increased the number of features fed to the classifiers, F
scores of the SVCs seemed to dropped. This is apparent from Figure 7 and Effigy 8. This leads to two conclusions. First, the samples in the dataset are dispersed, and the degree of dispersion (besprinkle) is notable. A statistical measure of besprinkle is the variance. High variance has led to the underfitting of the SVC, and as the number of features is increased, the underfitting increases as well. A plausible solution is the proper scaling of the information around the hateful. This over again serves every bit a trade-off equally scaling might sometimes lead to information loss, which does not reflect the real-life data, peculiarly in the instance of embeddings with vocabularies as large equally ours.
With fewer features, the decision purlieus hyperplanes that are formed become simpler. Therefore, hyperplanes with fifty features and 100 features are much simpler than those with 150 features, pertaining to the fact that an increase in characteristic numbers leads to an increase in the complication of hyperplane conclusion boundaries.
As seen in Figure 7 and Figure viii, when we increased the number of features, nigh all XGB classifiers improved their F
scores, while with fewer features, RF had better F
scores. This can be attributed to the bias–variance merchandise-off. RF is more than robust confronting overfitting and carries a low bias. At the same time, it does not work well with loftier variance. XGB, however, improves the bias and is hence less afflicted by the increase in variance as the number of features increase. It is besides susceptible to overfitting.
As is credible from Figure 7 and Effigy viii, SVCs behaved marginally improve with the Google pre-trained Word2Vec embedding (at par with RF and XGB), than with the GloVe pre-trained embedding. Word2Vec is an NN-based method that predicts the placement of i discussion with respect to the other words. GloVe, however, operates via two co-occurrence matrices and its fundamentals are frequency-of-utilize-based and not predictive. With a relatively small-scale vocabulary of virtually two thousand words, Word2Vec has worked well with complex mathematical SVCs; an embedded word vector also directly implies simpler hyperplanes.
In Tabular array 3, nosotros see that among the bachelor feature option methods, Chi-squared and RF gave the highest F
scores. The chi-squared examination is a statistical test that determines if one variable is independent of another. Information technology uses the chi-squared statistic as a measure. RF, on the other manus, is an ensemble of conclusion trees that are used to classify specified classes. While the chi-squared method is a hypothesis-driven method, RF is centred around conclusion trees. Both these methods are prone to noisy data but perform uncommonly well with smaller datasets with a more finite corpus such every bit ours.
A simple wait at Figure 11 reveals that feature selection methods gave much more prominent results with Google'southward pre-trained Word2Vec embedding than with the GloVe pre-trained embedding. The reason for this is similar to that of a previous observation: Word2Vec being an NN-based embedding, it tin can achieve better semantics even with a smaller dataset; on the other hand, GloVe, which is majorly dependent upon co-occurrence, fails to practise so. Hence, it is worth noting that the semantics captured by the Google pre-trained Word2Vec embedding are superior to those captured by the GloVe pre-trained embedding. Some other prominent reason is that the GloVe embedding was based on a corpus of articles that have now become outdated and exercise not bring as much context to a film review dataset every bit Google's Word2Vec does. Figure 11 clearly shows that the embeddings that have been trained here, namely the Word2Vec Skipgram and the Word2Vec CBOW, provided results that are not every bit accurate equally those provided by the Google Word2Vec and GloVe embeddings. The Google and GloVe word embeddings were trained on huge datasets with vocabularies of upward to 100 billion words. With ameliorate vocabularies and a larger corpus, word semantics were improve captured in these discussion embeddings. In contrast, our corpus had a fraction of those words. This led to appreciably less semantic word embeddings and consequentially, lower F
scores. A simple remedy is to employ a larger corpus to avoid any such cold start scenarios.
All the observations from Figure 11 were below the standard results. With the leading and average F
scores in the two-course category being 0.9742 (as recorded in Thongtan and Phienthrakul [43]) and 0.93 (in Yasen and Tedmori [44]), the F
scores achieved in our studies seem sub-standard. Firstly, our dataset is much smaller compared to the popular datasets used in the field. Secondly, a three-grade classification is much more circuitous than a ii-form classification. This is made even more circuitous by the imbalance we have in the dataset, which cannot be removed due to the persistent common cold commencement.
seven. Conclusions
In this paper, nosotros studied the problem of motion-picture show recommendation systems, where nosotros considered online movie reviews in order to propose movies to people. We proposed a dataset called JUMRv1 for the evolution of flick recommendation systems using iii-class SAs and performed an exhaustive experimentation of various models to nowadays the baseline results of the overall sentiment of the reviews. In social club to develop this database, we crawled, annotated, and cleaned the reviews taken from the popular movie review website called IMDB. To the best of our cognition, all popular enquiry works on flick recommendation systems take been performed considering these equally a ii-class classification trouble and with the use of older datasets. The novelty of our research is that it provides a large-scale dataset, with a high number of reviews besides every bit reviews for newer movies, which bring into context some words and phrases that pertain to the newest trends. It brings more realism into the field of movie review sentiment analysis as information technology is only natural for people to take indifferent opinions on movies. A wider range of sentiments makes the dataset more applicable to the real world. Our research paves the manner for farther inquiry into the field of iii-form sentiment classification for motion-picture show reviews.
Although these results are a cornerstone in the testing of the corresponding methods, the F1 scores that we achieved are significantly below the industry standard. The reasons are highly related to the length, class-imbalance, and complexity of the dataset, which provides us with the opportunity for improvement. Futurity work on JUMRv1 can explore other feature extraction techniques such equally the utilize of transformers and the northward-gram methodology. Subsequently, other ensemble methods can be used for farther investigation on increasing classification metrics. As seen in Section 3, in that location is clearly an imbalance in the data. The dataset is almost completely positively biased, and information technology is not piece of cake to remove that imbalance. Further improvement can be fabricated past adding more negative and indifferent reviews. It would not only aid the models train meliorate, merely will also provide more varieties to the word embeddings generated. It is always possible to add more reviews to the dataset, which would make it larger and hence provide us with more exam and railroad train data samples. As we take performed a general sentiment analysis here, we can leverage the dataset for multi-target-based sentiment analyses and execute an exhaustive ready of experiments for the same, pertaining to the fact that the annotation may nonetheless be extended to further enhance on our dataset.
Author Contributions
Conceptualization, R.S., A.G., Chiliad.C. and S.C.; methodology, R.S., G.C., Due south.C., A.M. and F.Due south.; investigation Thou.C., Southward.C. and A.G.; writing—original typhoon training, K.C., S.C. and A.G.; writing—review and editing, R.South., F.Southward., A.G., K.C. and S.C.; supervision, R.Southward. and F.S. All authors have read and agreed to the published the version of the manuscript.
Funding
This research involved no external funding.
Institutional Review Board Statement
Non applicable.
Informed Consent Argument
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Baid, P.; Gupta, A.; Chaplot, N. Sentiment analysis of movie reviews using machine learning techniques. Int. J. Comput. Appl. 2017, 179, 45–49. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. arXiv 2004, arXiv:cs/0409058. [Google Scholar]
- Elghazaly, T.; Mahmoud, A.; Hefny, H.A. Political sentiment analysis using twitter data. In Proceedings of the International Conference on Internet of things and Cloud Computing, Cambridge, United kingdom of great britain and northern ireland, 23 February—22 March 2016; pp. 1–5. [Google Scholar]
- Pratiwi, A.I. On the feature option and nomenclature based on information gain for document sentiment analysis. Appl. Comput. Intell. Soft Comput. 2018, 2018, 1407817. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using auto learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Tripathy, A.; Agrawal, A.; Rath, Due south.Thousand. Classification of sentiment reviews using n-gram car learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Zou, H.; Tang, Ten.; Xie, B.; Liu, B. Sentiment classification using machine learning techniques with syntax features. In Proceedings of the 2015 International Conference on Computational Scientific discipline and Computational Intelligence (CSCI), Las Vegas, NV, The states, vii–9 December 2015; pp. 175–179. [Google Scholar]
- Ukhti Ikhsani Larasati, I.U.; Much Aziz Muslim, I.U.; Riza Arifudin, I.U.; Alamsyah, I.U. Meliorate the Accuracy of Support Vector Machine Using Chi Square Statistic and Term Frequency Inverse Document Frequency on Moving picture Review Sentiment Analysis. Sci. J. Inform. 2019, 6, 138–149. [Google Scholar]
- Ray, B.; Garain, A.; Sarkar, R. An ensemble-based hotel recommender organisation using sentiment analysis and aspect categorization of hotel reviews. Appl. Soft Comput. 2021, 98, 106935. [Google Scholar] [CrossRef]
- Fang, 10.; Zhan, J. Sentiment analysis using product review data. J. Big Data 2015, 2, v. [Google Scholar] [CrossRef]
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Automobile Learning for Signal Processing (MLSP), Salerno, Italia, thirteen–16 September 2016; pp. 1–6. [Google Scholar]
- Manek, A.S.; Shenoy, P.D.; Mohan, Yard.C.; Venugopal, Chiliad. Aspect term extraction for sentiment analysis in large movie reviews using Gini Index characteristic selection method and SVM classifier. World Broad Web 2017, 20, 135–154. [Google Scholar] [CrossRef]
- Liao, S.; Wang, J.; Yu, R.; Sato, K.; Cheng, Z. CNN for situations understanding based on sentiment analysis of twitter data. Procedia Comput. Sci. 2017, 111, 376–381. [Google Scholar] [CrossRef]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. Evaluation datasets for Twitter sentiment analysis: A survey and a new dataset, the STS-Gilded. In Proceedings of the 1st Interantional Workshop on Emotion and Sentiment in Social and Expressive Media: Approaches and Perspectives from AI (ESSEM 2013), Turin, Italy, iii December 2013. [Google Scholar]
- Singh, T.; Nayyar, A.; Solanki, A. Multilingual opinion mining moving-picture show recommendation system using RNN. In Proceedings of First International Briefing on Computing, Communications, and Cyber-Security (IC4S 2019); Springer: Berlin/Heidelberg, Germany, 2020; pp. 589–605. [Google Scholar]
- Ibrahim, 1000.; Bajwa, I.Due south.; Ul-Amin, R.; Kasi, B. A neural network-inspired arroyo for improved and true movie recommendations. Comput. Intell. Neurosci. 2019, 2019, 4589060. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Sun, A.; Han, J.; Liu, Y.; Zhu, 10. Sentiment analysis by capsules. In Proceedings of the 2018 World wide web Conference, Lyon, France, 23–27 April 2018; pp. 1165–1174. [Google Scholar]
- Firmanto, A.; Sarno, R. Prediction of motion-picture show sentiment based on reviews and score on rotten tomatoes using sentiwordnet. In Proceedings of the 2018 International Seminar on Application for Engineering of Information and Communication, Semarang, Indonesia, 21–22 September 2018; pp. 202–206. [Google Scholar]
- Miranda, E.; Aryuni, One thousand.; Hariyanto, R.; Surya, Eastward.S. Sentiment Assay using Sentiwordnet and Car Learning Approach (Indonesia general election stance from the twitter content). In Proceedings of the 2019 International Briefing on Information Management and Technology (ICIMTech), Denpasar, Indonesia, nineteen–20 August 2019; Volume ane, pp. 62–67. [Google Scholar]
- Hong, J.; Nam, A.; Cai, A. Multi-Class Text Sentiment Assay. 2019. Available online: http://cs229.stanford.edu/proj2019aut/information/assignment_308832_raw/26644050.pdf (accessed on 29 September 2021).
- Attia, M.; Samih, Y.; Elkahky, A.; Kallmeyer, Fifty. Multilingual multi-class sentiment nomenclature using convolutional neural networks. In Proceedings of the Eleventh International Conference on Linguistic communication Resources and Evaluation (LREC 2018), Miyazaki, Japan, vii–12 May 2018. [Google Scholar]
- Sharma, Southward.; Srivastava, Southward.; Kumar, A.; Dangi, A. Multi-Class Sentiment Analysis Comparing Using Support Vector Machine (SVM) and BAGGING Technique-An Ensemble Method. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE), Kuala Lumpur, Malaysia, xi–12 July 2018; pp. 1–6. [Google Scholar]
- Liu, Y.; Bi, J.W.; Fan, Z.P. Multi-class sentiment classification: The experimental comparisons of feature choice and machine learning algorithms. Practiced Syst. Appl. 2017, 80, 323–339. [Google Scholar] [CrossRef]
- Richardson, L. Beautiful Soup Documentation. 2007. Available online: https://beautiful-soup-4.readthedocs.io/en/latest/ (accessed on 29 September 2021).
- Sharma, A.; Dey, Southward. Performance investigation of characteristic selection methods and sentiment lexicons for sentiment analysis. IJCA Spec. Issue Adv. Comput. Commun. Technol. HPC Appl. 2012, 3, 15–20. [Google Scholar]
- Rahman, A.; Hossen, Chiliad.South. Sentiment analysis on movie review data using car learning approach. In Proceedings of the 2019 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, People's republic of bangladesh, 27–28 September 2019; pp. 1–iv. [Google Scholar]
- Garain, A.; Mahata, South.1000. Sentiment Analysis at SEPLN (TASS)-2019: Sentiment Analysis at Tweet Level Using Deep Learning. arXiv 2019, arXiv:1908.00321. [Google Scholar]
- Garain, A.; Mahata, S.One thousand.; Dutta, S. Normalization of Numeronyms using NLP Techniques. In Proceedings of the 2020 IEEE Calcutta Conference (CALCON), Kolkata, Bharat, 28–29 February 2020; pp. 7–nine. [Google Scholar]
- Garain, A. Humour Analysis Based on Human Annotation (HAHA)-2019: Humor Analysis at Tweet Level Using Deep Learning. 2019. Available online: https://www.researchgate.cyberspace/publication/335022260_Humor_Analysis_based_on_Human_Annotation_HAHA-2019_Humor_Analysis_at_Tweet_Level_using_Deep_Learning (accessed on 29 September 2021).
- Honnibal, M.; Montani, I.; Van Landeghem, Due south.; Boyd, A. spaCy: Industrial-Strength Natural language Processing in Python. 2020. Available online: https://spacy.io/ (accessed on 29 September 2021). [CrossRef]
- Mikolov, T.; Chen, Chiliad.; Corrado, G.; Dean, J. Efficient interpretation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Give-and-take Representation. In Proceedings of the Empirical Methods in Natural Linguistic communication Processing (EMNLP), Doha, Qatar, 25–29 Oct 2014; pp. 1532–1543. [Google Scholar]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef]
- Ghosh, K.K.; Begum, Due south.; Sardar, A.; Adhikary, S.; Ghosh, G.; Kumar, Thousand.; Sarkar, R. Theoretical and empirical analysis of filter ranking methods: Experimental report on benchmark DNA microarray data. Adept Syst. Appl. 2021, 169, 114485. [Google Scholar] [CrossRef]
- Forman, K. An extensive empirical written report of feature selection metrics for text classification. J. Mach. Learn. Res. 2003, iii, 1289–1305. [Google Scholar]
- Li, J.; Cheng, One thousand.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature pick: A data perspective. ACM Comput. Surv. 2017, 50, ane–45. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, Eastward.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Pandas Evolution Team. pandas-dev/pandas: Pandas 2020. Available online: https://zenodo.org/record/3630805#.YWD91o4zZPY (accessed on 29 September 2021). [CrossRef]
- Van Rossum, One thousand. The Python Library Reference, Release 3.8.ii; Python Software Foundation: Wilmington, DE, USA, 2020. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, K.; Prettenhofer, P.; Weiss, R.; Dubourg, 5.; et al. Scikit-acquire: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2nd graphics surround. Comput. Sci. Eng. 2007, 9, ninety–95. [Google Scholar] [CrossRef]
- Thongtan, T.; Phienthrakul, T. Sentiment nomenclature using document embeddings trained with cosine similarity. In Proceedings of the 57th Almanac Coming together of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 28 July 2019; pp. 407–414. [Google Scholar]
- Yasen, One thousand.; Tedmori, S. Movies Reviews sentiment analysis and classification. In Proceedings of the 2019 IEEE Jordan International Articulation Conference on Electrical Applied science and Information technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 860–865. [Google Scholar]
Figure 1. Fundamental modules of the sentiment analysis-based Motion-picture show Recommendation System used in this research report.
Figure one. Key modules of the sentiment analysis-based Pic Recommendation System used in this research study.
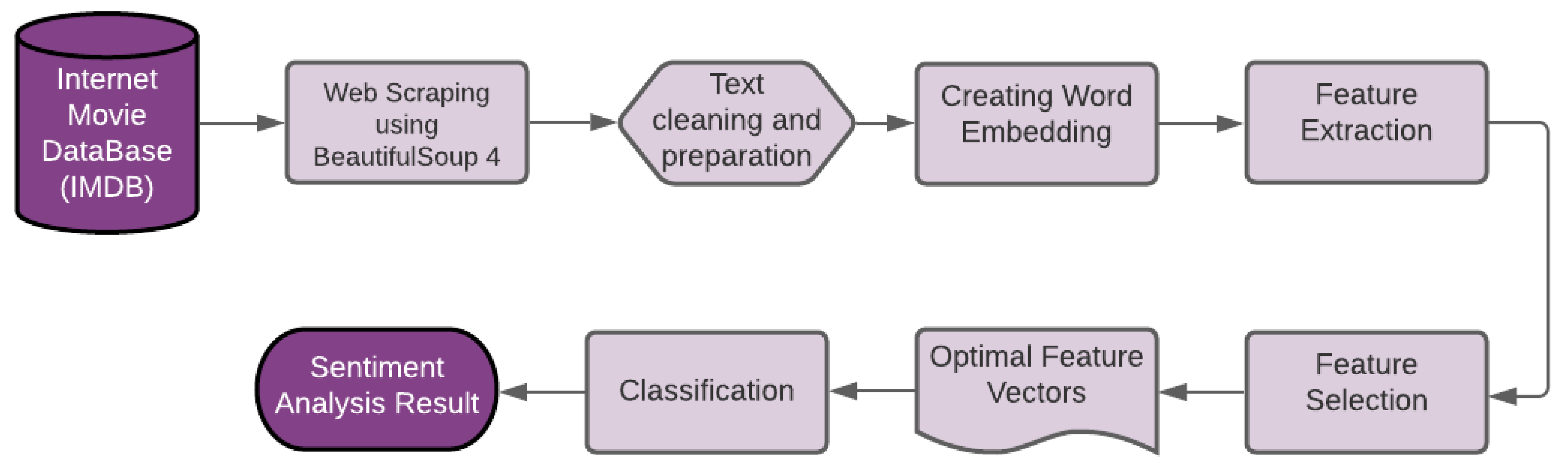
Figure 3. An illustration of the flow of data in the CBOW (left) and Skipgram (right) training methods.
Figure 3. An analogy of the flow of data in the CBOW (left) and Skipgram (correct) training methods.
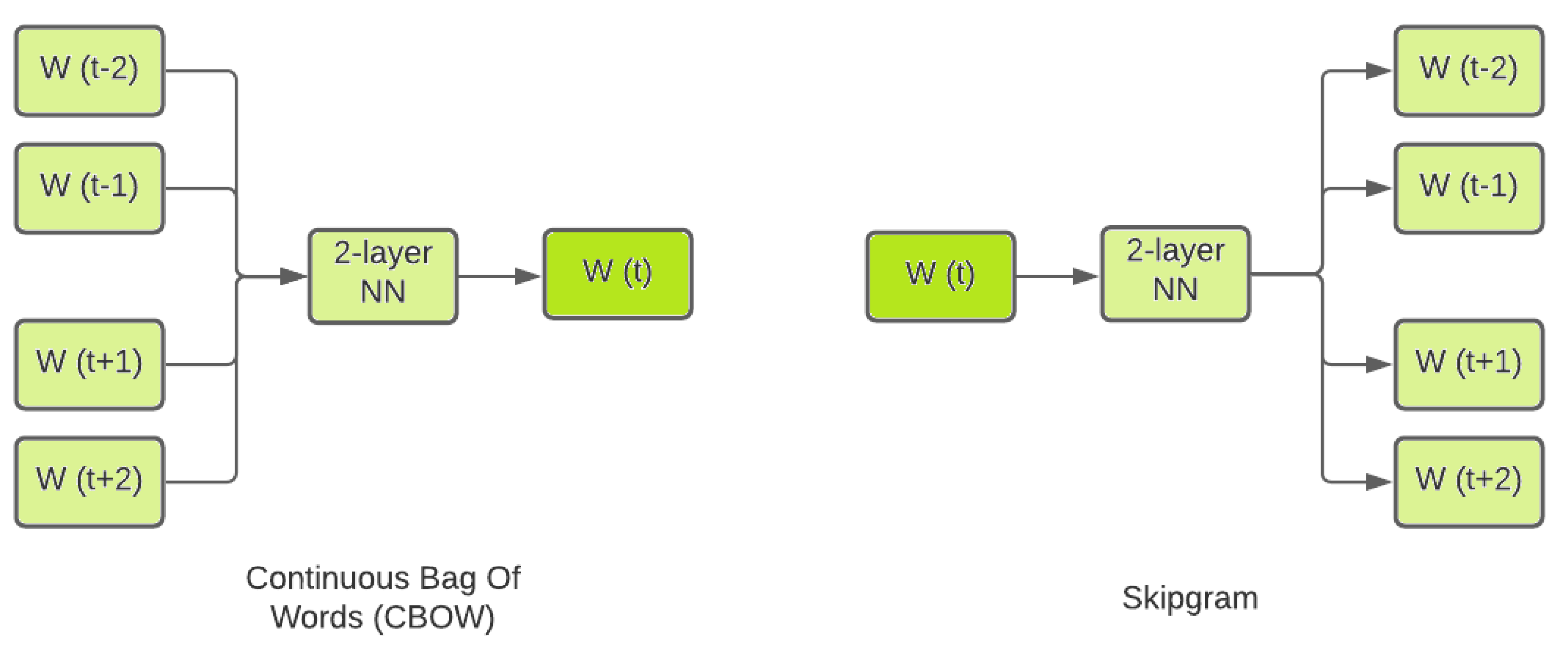
Figure 4. Workflow of the (a) filter-based and (b) wrapper-based feature selection methods.
Figure 4. Workflow of the (a) filter-based and (b) wrapper-based characteristic choice methods.
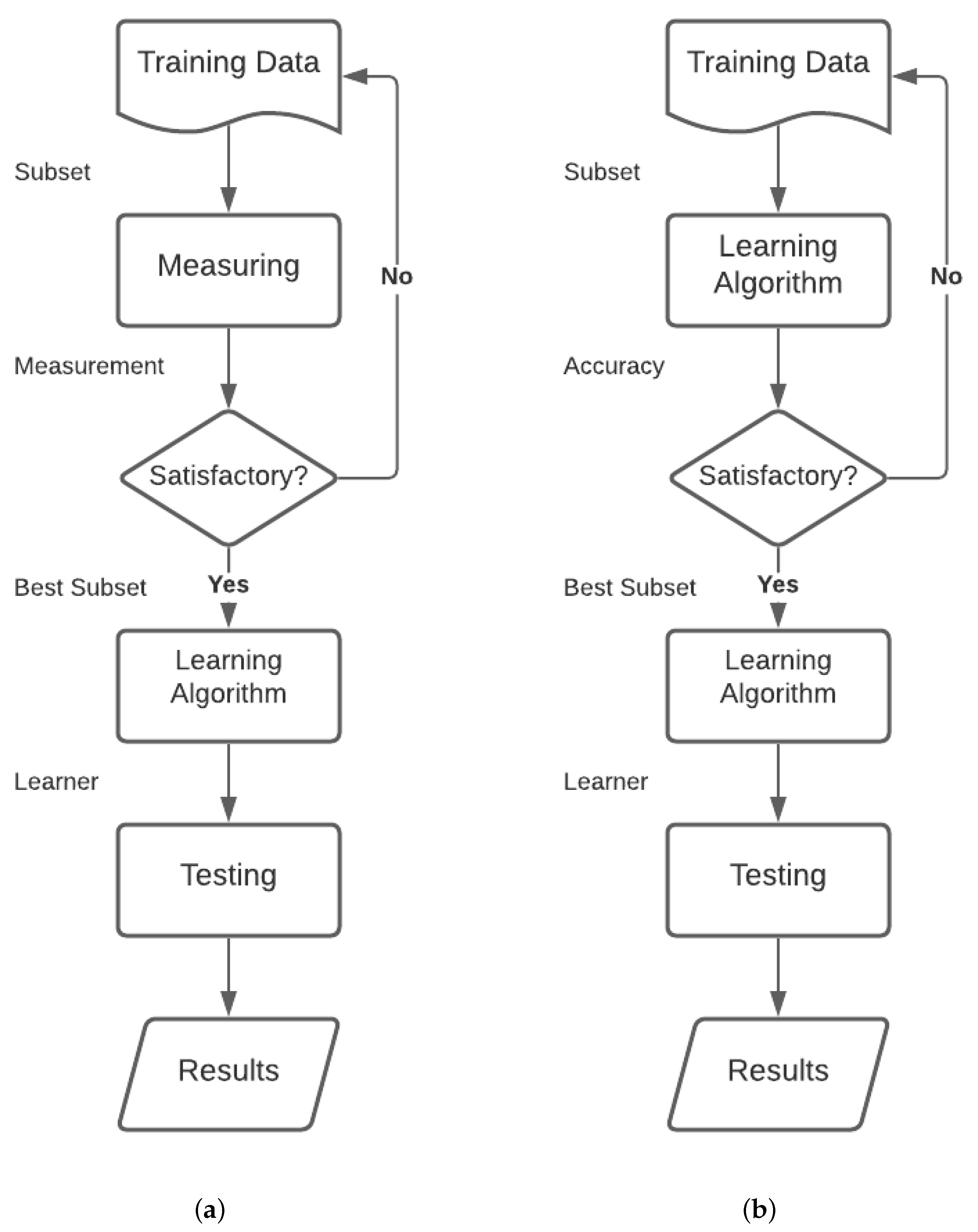
Figure 5. F
scores for GloVe embeddings, without whatsoever feature selection methods.
Effigy v. F
scores for GloVe embeddings, without any feature selection methods.
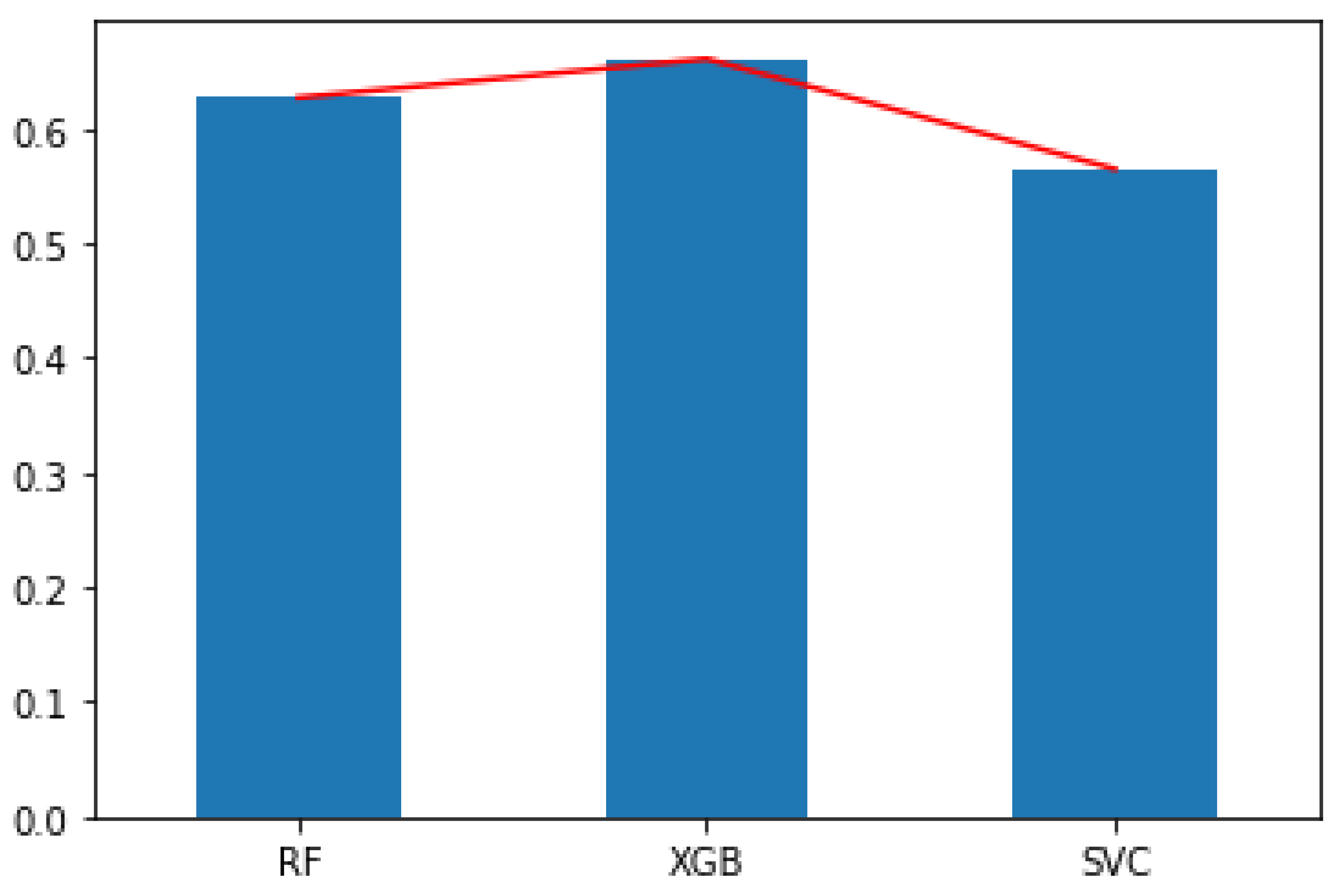
Figure six. F
Scores for Google pre-trained word embedding, without any feature selection methods.
Figure 6. F
Scores for Google pre-trained word embedding, without whatsoever feature choice methods.
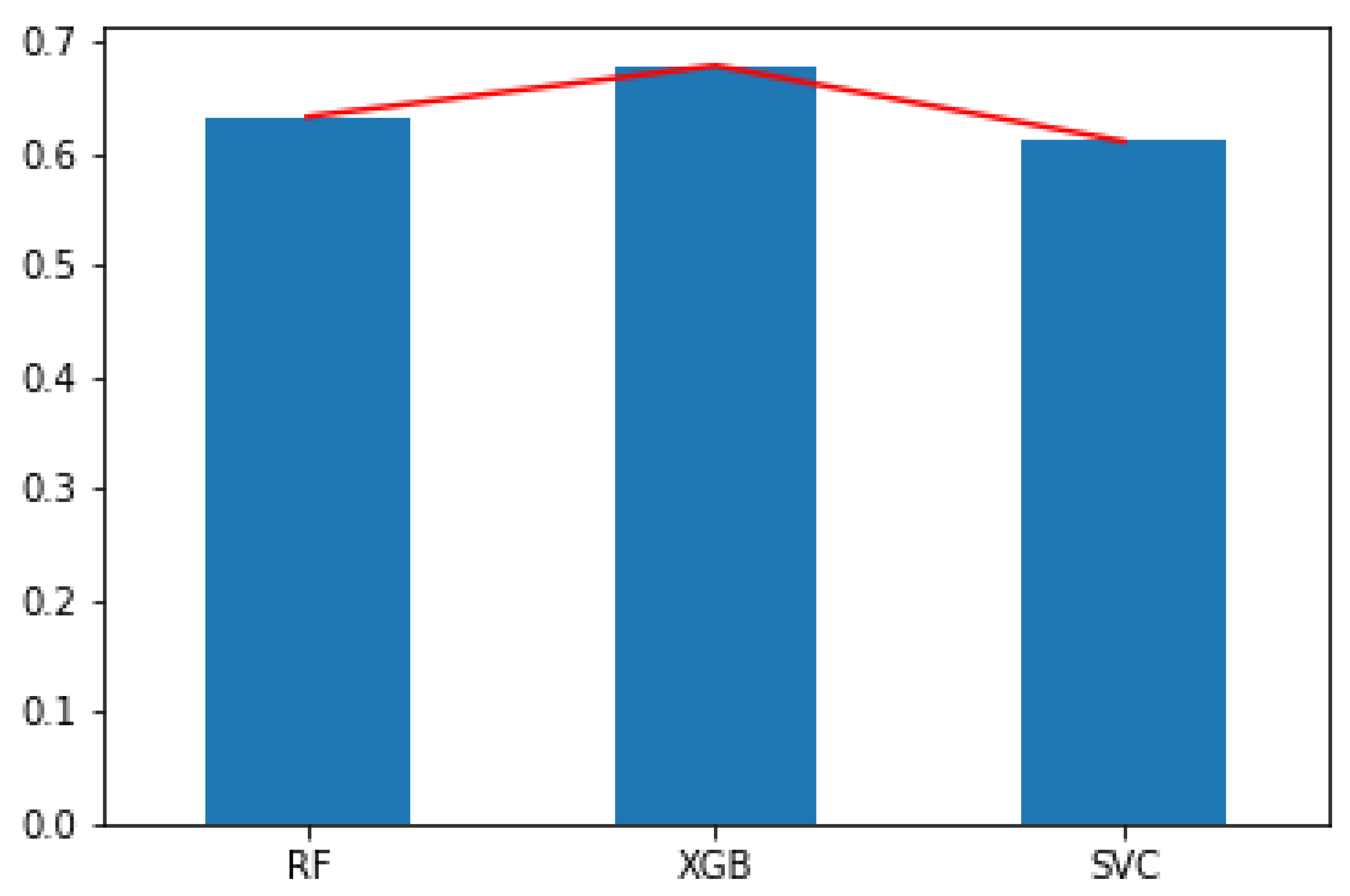
Figure seven. Bar graph showing the F
scores on GloVe embedding, for all combinations of characteristic selection methods and number of features.
Effigy 7. Bar graph showing the F
scores on GloVe embedding, for all combinations of feature selection methods and number of features.
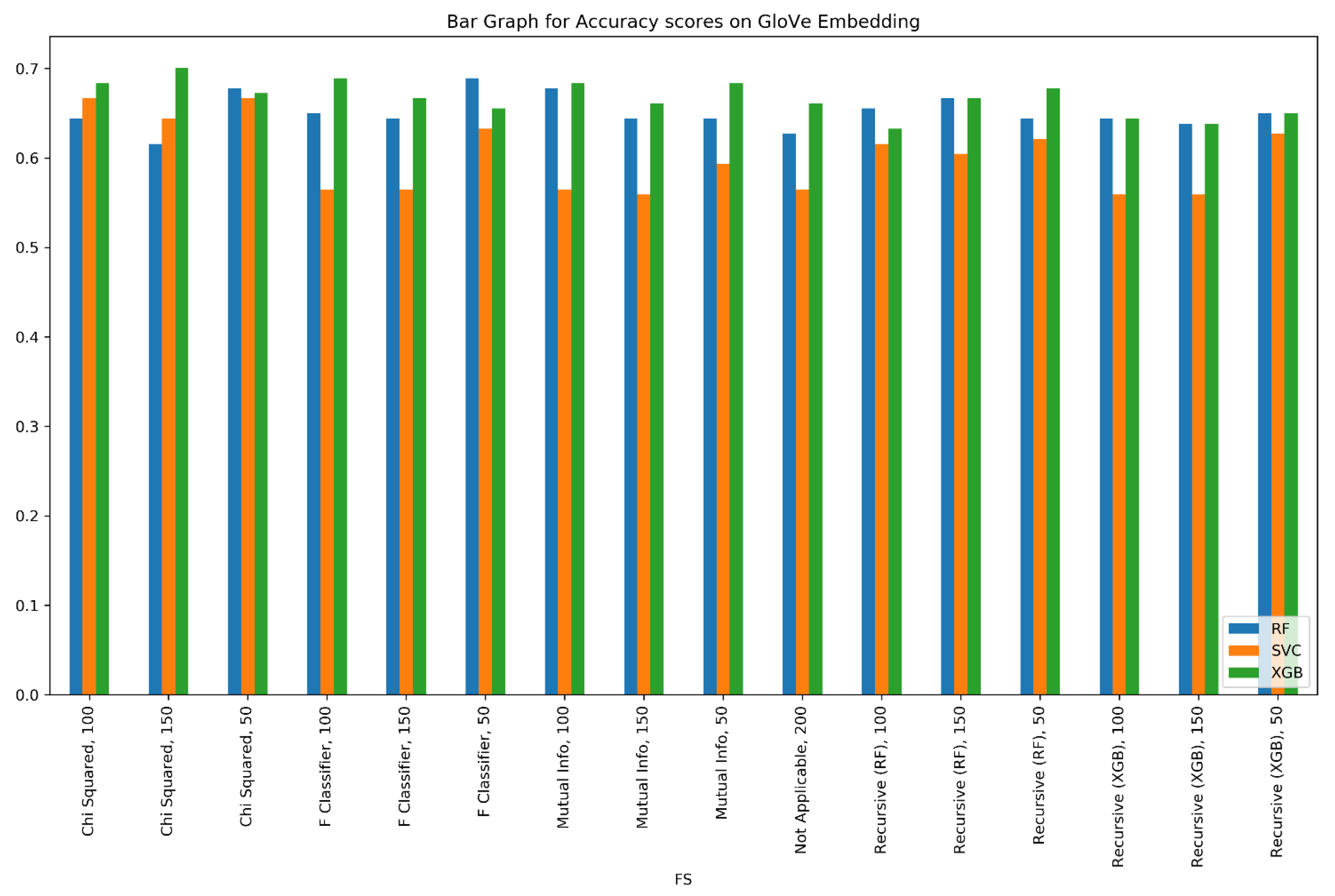
Figure 8. Bar graph for F
scores on Google'southward pre-trained embedding, for all combinations of feature choice methods and number of features.
Figure eight. Bar graph for F
scores on Google's pre-trained embedding, for all combinations of characteristic selection methods and number of features.
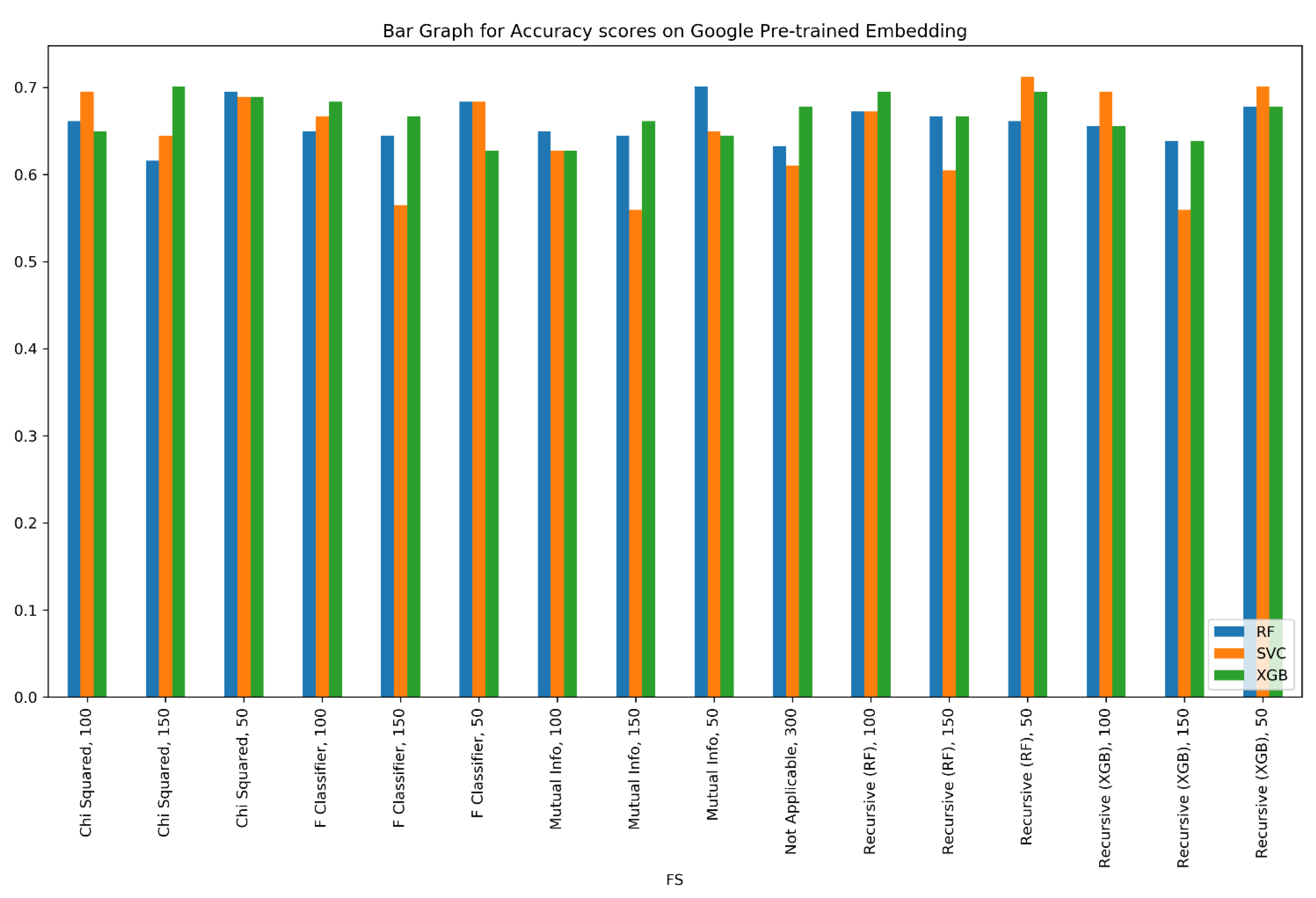
Figure 9. F
scores of self-trained Word2Vec embedding with the CBOW method.
Figure nine. F
scores of cocky-trained Word2Vec embedding with the CBOW method.
Effigy x. F
scores of self-trained Word2Vec embedding with the Skipgram method.
Effigy 10. F
scores of cocky-trained Word2Vec embedding with the Skipgram method.
Effigy 11. Hateful F
scores for all the discussion embeddings.
Figure 11. Mean F
scores for all the word embeddings.
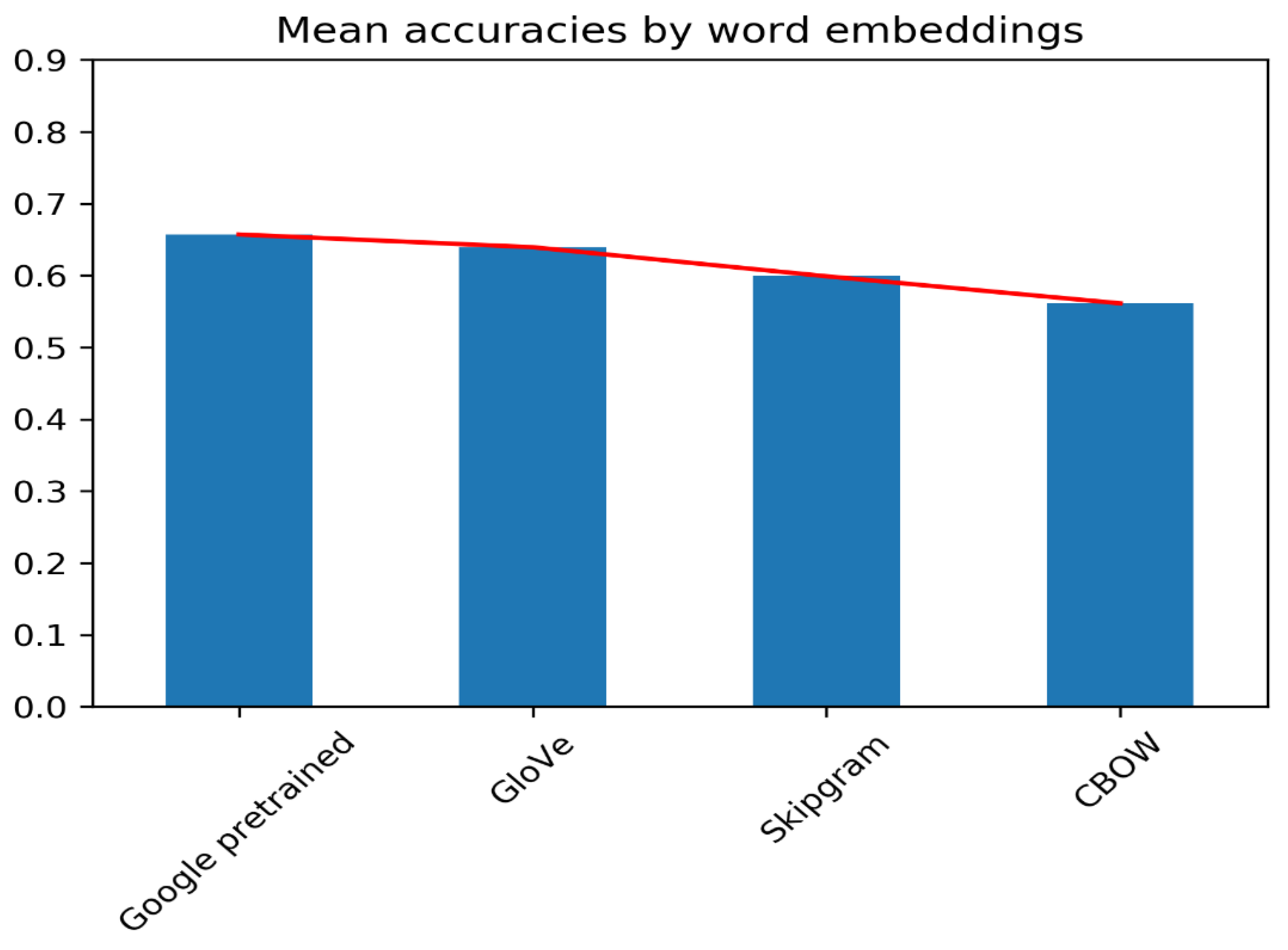
Table i. Examples of movie reviews for each class.
Table 1. Examples of movie reviews for each class.
| Review | Sentiment | Corresponding Note |
|---|---|---|
| "Amazing. Steven Spielberg always makes masterpieces…" | Positive | 1 |
| "Mediocre performance by Jake Gyllenhaal. The plot is good, worth a watch…" | Neutral | 0 |
| "This moving picture is an utter disaster. This is nada like the book, full of inaccuracies. A vitrify batman is unnatural…" | Negative | −1 |
Tabular array 2. How JUMRv1 compares to popular moving picture review datasets.
Table 2. How JUMRv1 compares to popular motion picture review datasets.
| Dataset | Year of Creation | Year When Last Modified | No. of Reviews | No. of Classes |
|---|---|---|---|---|
| Polarity Dataset (Cornell) | 2002 | 2004 | 2000 | 2 |
| Large Movie Review Dataset (Stanford) | 2011 | - | 50,000 | 2 |
| Rotten Tomatoes Dataset | 2020 | - | 17,000 | 2 |
| STS-Gold | 2015 | 2016 | 2034 | 2 |
| JUMR v1.0 | 2021 | - | 1422 | iii |
Tabular array three. Fone scores obtained by using GloVe pre-trained embeddings and selecting 150, 100, and 50 features.
Table 3. F1 scores obtained by using GloVe pre-trained embeddings and selecting 150, 100, and 50 features.
| Characteristic Selection | Features Selected | Classifier | F1-Score |
|---|---|---|---|
| Recursive (RF) | 150 | RF | 0.6667 |
| Recursive (RF) | XGB | 0.6667 | |
| Recursive (RF) | SVC | 0.6045 | |
| Recursive (XGB) | RF | 0.6384 | |
| Recursive (XGB) | XGB | 0.6384 | |
| Recursive (XGB) | SVC | 0.5593 | |
| Chi-Squared | RF | 0.6158 | |
| Chi-Squared | XGB | 0.7006 | |
| Chi-Squared | SVC | 0.6441 | |
| Mutual Info | RF | 0.6441 | |
| Mutual Info | XGB | 0.661 | |
| Mutual Info | SVC | 0.5593 | |
| F Classifier | RF | 0.6441 | |
| F Classifier | XGB | 0.6667 | |
| F Classifier | SVC | 0.565 | |
| Recursive (RF) | 100 | RF | 0.6553 |
| Recursive (RF) | XGB | 0.6327 | |
| Recursive (RF) | SVC | 0.6158 | |
| Recursive (XGB) | RF | 0.644 | |
| Recursive (XGB) | XGB | 0.644 | |
| Recursive (XGB) | SVC | 0.5593 | |
| Chi-Squared | RF | 0.644 | |
| Chi-Squared | XGB | 0.6836 | |
| Chi-Squared | SVC | 0.6666 | |
| Mutual Info | RF | 0.6779 | |
| Mutual Info | XGB | 0.6836 | |
| Common Info | SVC | 0.5649 | |
| F Classifier | RF | 0.6497 | |
| F Classifier | XGB | 0.6892 | |
| F Classifier | SVC | 0.5649 | |
| Recursive (RF) | fifty | RF | 0.644 |
| Recursive (RF) | XGB | 0.6779 | |
| Recursive (RF) | SVC | 0.6214 | |
| Recursive (XGB) | RF | 0.649717 | |
| Recursive (XGB) | XGB | 0.649715 | |
| Recursive (XGB) | SVC | 0.6271 | |
| Chi-Squared | RF | 0.6779 | |
| Chi-Squared | XGB | 0.6723 | |
| Chi-Squared | SVC | 0.6666 | |
| Common Info | RF | 0.644 | |
| Common Info | XGB | 0.6836 | |
| Mutual Info | SVC | 0.5932 | |
| F Classifier | RF | 0.6892 | |
| F Classifier | XGB | 0.6553 | |
| F Classifier | SVC | 0.6327 |
Table 4. Fi scores obtained by using Google pre-trained Word2Vec embedding and selecting 150, 100, and 50 features.
Table 4. Fane scores obtained by using Google pre-trained Word2Vec embedding and selecting 150, 100, and 50 features.
| Characteristic Selection | Features Selected | Classifier | F1 Score |
|---|---|---|---|
| Recursive (RF) | 150 | RF | 0.6667 |
| Recursive (RF) | XGB | 0.6667 | |
| Recursive (RF) | SVC | 0.6045 | |
| Recursive (XGB) | RF | 0.6384 | |
| Recursive (XGB) | XGB | 0.6384 | |
| Recursive (XGB) | SVC | 0.5593 | |
| Chi-Squared | RF | 0.6158 | |
| Chi-Squared | XGB | 0.7006 | |
| Chi-Squared | SVC | 0.6441 | |
| Mutual Info | RF | 0.6441 | |
| Mutual Info | XGB | 0.661 | |
| Mutual Info | SVC | 0.5593 | |
| F Classifier | RF | 0.6441 | |
| F Classifier | XGB | 0.6667 | |
| F Classifier | SVC | 0.565 | |
| Recursive (RF) | 100 | RF | 0.6723 |
| Recursive (RF) | XGB | 0.6949 | |
| Recursive (RF) | SVC | 0.6723 | |
| Recursive (XGB) | RF | 0.6553 | |
| Recursive (XGB) | XGB | 0.6553 | |
| Recursive (XGB) | SVC | 0.6949 | |
| Chi-Squared | RF | 0.661 | |
| Chi-Squared | XGB | 0.6497 | |
| Chi-Squared | SVC | 0.6949 | |
| Common Info | RF | 0.6497 | |
| Mutual Info | XGB | 0.6271 | |
| Mutual Info | SVC | 0.6271 | |
| F Classifier | RF | 0.6497 | |
| F Classifier | XGB | 0.6836 | |
| F Classifier | SVC | 0.6666 | |
| Recursive (RF) | fifty | RF | 0.661 |
| Recursive (RF) | XGB | 0.6949 | |
| Recursive (RF) | SVC | 0.712 | |
| Recursive (XGB) | RF | 0.678 | |
| Recursive (XGB) | XGB | 0.678 | |
| Recursive (XGB) | SVC | 0.7006 | |
| Chi-Squared | RF | 0.695 | |
| Chi-Squared | XGB | 0.6892 | |
| Chi-Squared | SVC | 0.6892 | |
| Mutual Info | RF | 0.7006 | |
| Common Info | XGB | 0.6441 | |
| Mutual Info | SVC | 0.6497 | |
| F Classifier | RF | 0.6836 | |
| F Classifier | XGB | 0.6271 | |
| F Classifier | SVC | 0.6836 |
Table 5. Embeddings: Custom CBOW, Skipgram, Word2Vec (trained by our group). Features: 100.
Table 5. Embeddings: Custom CBOW, Skipgram, Word2Vec (trained by our group). Features: 100.
| Embedding | Classifier | F1 Score |
|---|---|---|
| CBOW | RF | 0.54802 |
| CBOW | XGB | 0.58192 |
| CBOW | SVC | 0.55367 |
| Skipgram | SVC | 0.55367 |
| Skipgram | RF | 0.61017 |
| Skipgram | XGB | 0.63277 |
Table 6. Confusion matrix for Glove embedding with the RFE(RF) feature pick method; fifty features.
Tabular array 6. Confusion matrix for Glove embedding with the RFE(RF) feature selection method; l features.
Table 7. Confusion matrix for Glove Embedding with characteristic selection method of F Classifier, 100 features.
Tabular array 7. Confusion matrix for Glove Embedding with feature selection method of F Classifier, 100 features.
Table viii. Defoliation matrix for Glove embedding with the RFE(RF) feature pick method; 100 features.
Table 8. Confusion matrix for Glove embedding with the RFE(RF) feature choice method; 100 features.
Table nine. Defoliation matrix for Glove embedding with the Chi-squared feature selection method; 100 features.
Table 9. Confusion matrix for Glove embedding with the Chi-squared feature option method; 100 features.
Table 10. Confusion matrix for Glove embedding with F Classifier feature selection method and 100 features.
Table 10. Confusion matrix for Glove embedding with F Classifier feature selection method and 100 features.
Table 11. Confusion matrix for Glove embedding with the RFE (RF) feature option method; 150 features.
Tabular array 11. Confusion matrix for Glove embedding with the RFE (RF) feature selection method; 150 features.
Table 12. Confusion matrix for Glove embedding with the Chi-Squared characteristic selection method; 150 features.
Table 12. Confusion matrix for Glove embedding with the Chi-Squared characteristic option method; 150 features.
Table 13. Confusion matrix for Word2Vec embedding with the RFE (RF) characteristic selection method; 100 features.
Table 13. Confusion matrix for Word2Vec embedding with the RFE (RF) feature option method; 100 features.
Table 14. Confusion matrix for Glove embedding with the RFE (RF) feature selection method; 150 features.
Table 14. Confusion matrix for Glove embedding with the RFE (RF) feature selection method; 150 features.
Table 15. Confusion matrix for Word2Vec embedding with the RFE (RF) feature pick method; 150 features.
Table 15. Confusion matrix for Word2Vec embedding with the RFE (RF) feature choice method; 150 features.
| Publisher's Notation: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 past the authors. Licensee MDPI, Basel, Switzerland. This commodity is an open up access commodity distributed under the terms and conditions of the Artistic Eatables Attribution (CC By) license (https://creativecommons.org/licenses/by/4.0/).
rodriquezexpet1994.blogspot.com
Source: https://www.mdpi.com/2076-3417/11/20/9381/htm
0 Response to "Human Level Performe to Sentiment Classification of Movie Review"
Post a Comment